Worker deployment and performance
This document outlines best practices for deploying and optimizing Workers to ensure high performance, reliability, and scalability. It covers deployment strategies, scaling techniques, tuning recommendations, and monitoring approaches to help you get the most out of your Temporal Workers.
We also provide a reference application, the Order Management System (OMS), that demonstrates the deployment best practices in action. You can find the OMS codebase on GitHub.
Deployment and lifecycle management
Well-designed Worker deployment ensures resilience, observability, and maintainability. A Worker should be treated as a long-running service that can be deployed, upgraded, and scaled in a controlled way.
Package and configure Workers for flexibility
Workers should be artifacts produced by a CI/CD pipeline. Inject all required parameters for connecting to Temporal Cloud or a self-hosted Temporal Service at runtime via environment variables, configuration files, or command-line parameters. This allows for more granularity, easier testability, easier upgrades, scalability, and isolation of Workers.
In the order management reference app, Workers are packaged as Docker images with configuration provided via environment variables and mounted configuration files. The following Dockerfile uses a multi-stage build to create a minimal, production-ready Worker image:
FROM golang:1.23.8 AS oms-builder
WORKDIR /usr/src/oms
COPY go.mod go.sum ./
RUN
\
go mod download
COPY app ./app
COPY cmd ./cmd
RUN
\
CGO_ENABLED=0 go build -v -o /usr/local/bin/oms ./cmd/oms
FROM busybox AS oms-worker
This Dockerfile uses a multi-stage build pattern with two stages:
-
oms-builderstage: compiles the Worker binary.- Copies dependency files and downloads dependencies using BuildKit cache mounts to speed up subsequent builds.
- Copies the application code and builds a statically linked binary that doesn't require external libraries at runtime.
-
oms-workerstage: creates a minimal final image.- Copies only the compiled binary from the
oms-builderstage - Sets the entrypoint to run the Worker process.
- Copies only the compiled binary from the
The entrypoint oms worker starts the Worker process, which reads configuration from environment variables at runtime.
For example, the
Billing Worker deployment in Kubernetes
uses environment variables to configure the Worker:
deployments/k8s/billing-worker-deployment.yaml
# ...
kind: Deployment
# ...
# ...
# ...
metadata:
# ...
app.kubernetes.io/component: billing-worker
Separate Task Queues logically
Use separate Task Queues for distinct workloads. This isolation allows you to control rate limiting, prioritize certain workloads, and prevent one workload from starving another. For each Task Queue, ensure you configure at least two Workers to poll the Task Queue.
In the order management reference app, each microservice has its own Task Queue. For example, the Billing Worker polls
the billing Task Queue, while the Order Worker polls the order Task Queue. This separation allows each service to
scale independently based on its workload.
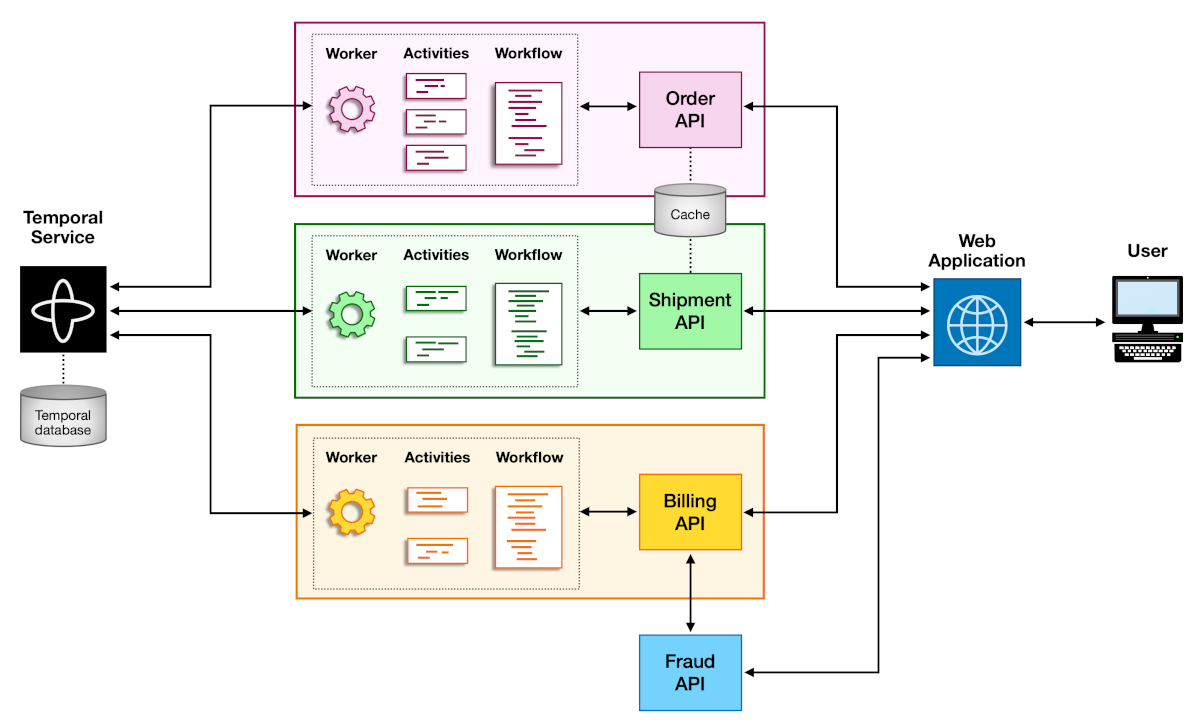
Diagram showing separate Task Queues for different Workers
The following code snippet shows how the Billing Worker is set up to poll its Task Queue. The default value for
TaskQueue comes from the api.go configuration file and is set to billing.
func RunWorker(ctx context.Context, config config.AppConfig, client client.Client) error {
w := worker.New(client, TaskQueue, worker.Options{
MaxConcurrentWorkflowTaskPollers: 8,
MaxConcurrentActivityTaskPollers: 8,
})
w.RegisterWorkflow(Charge)
w.RegisterActivity(&Activities{FraudCheckURL: config.FraudURL})
return w.Run(temporalutil.WorkerInterruptFromContext(ctx))
}
Use Worker Versioning to safely deploy new Workflow code
Use Worker Versioning to deploy new Workflow code without breaking running Executions.
Worker Versioning lets you map each Workflow Execution to a specific Worker Deployment Version identified by a build ID.
This guarantees that pinned Workflows always run on the same Worker version where they started.
To learn more about versioning Workflows, see the Workflow Versioning guide.
In addition to Worker Versioning, you can also use Patching to introduce changes to your Workflow code without breaking running Executions. Patching reduces complexity on the infrastructure side compared to Worker Versioning, but it introduces some complexity on the Workflow code side. Choose the approach that best fits your needs.
Manage Event History growth
If a Worker goes offline, and another Worker picks up the same Workflow Execution, the new Worker must replay the existing Event History to resume the Workflow Execution. If the Event History is too large or has too many Events, it will affect the performance of the new Worker, and may even cause timeout errors well before the hard limit of 51,200 events is reached.
We recommend not exceeding a few thousand Events in a single Workflow Execution. The best way to handle Event History growth is to use the Continue-As-New mechanism to continue under a new Workflow Execution with a new Event History, repeating this process as you approach the limits again.
All Temporal SDKs provide functions to suggest when to use Continue-As-New. For
example, the Python SDK has the
is_continue_as_new_suggested()
function that returns a bool indicating whether to use Continue-As-New.
In addition to the number of Events in the Event History, also monitor the size of the Event History. Input parameters and output values of both Workflows and Activities are stored in the Event History. Storing large amounts of data can lead to performance problems, so the Temporal Cluster limits both the size of the Event History and values stored within it. A Workflow Execution may be terminated if the size of any payload, which includes the input passed into, or the result returned by, an Activity or Workflow, exceeds 2 MB, or if the entire Event History exceeds 50 MB.
To avoid hitting these limits, avoid passing large amounts of data into and out of Workflows and Activities. A common way of reducing payload and Event History size is by using the Claim Check pattern, which is widely used with messaging systems such as Apache Kafka. Instead of passing a large amount of data into your function, store that data external to Temporal, perhaps in a database or file system. Pass the identifier for the data, such as the primary key or path, into the function, and use an Activity to retrieve it as needed. If your Activity produces a large amount of data, you could use a similar approach, writing that data to an external system and returning as output an identifier that could subsequently be used to retrieve it.
Scaling, monitoring, and tuning
Scaling and tuning are critical to Worker performance and cost efficiency. The goal is to balance concurrency, throughput, and resource utilization while maintaining low Task latency.
Interpret metrics as a whole
No single metric tells the full story. The following are some of the most useful Worker-related metrics to monitor. We recommend having all metrics listed below on your Worker monitoring dashboard. When you observe anomalies, correlate across multiple metrics to identify root causes.
- Worker CPU and memory utilization
workflow_task_schedule_to_start_latencyandactivity_task_schedule_to_start_latencyworker_task_slots_availabletemporal_long_request_failure,temporal_request_failure,temporal_long_request_latency, andtemporal_request_latency
For example, Schedule-to-Start latency measures how long a Task waits in the queue before a Worker starts it. High latency means your Workers or pollers can’t keep up with incoming Tasks, but the root cause depends on your resource metrics:
- High Schedule-to-Start latency and high CPU/memory: Workers are saturated. Scale up your Workers or add more Workers. It's also possible your Workers are blocked on Activities. Refer to Troubleshooting - Depletion of Activity Task Slots for guidance.
- High Schedule-to-Start latency and low CPU/memory: Workers are underutilized. Increase the number of pollers, executor
slots, or both. If this is accompanied by high
temporal_long_request_latencyortemporal_long_request_failure, your Workers are struggling to reach the Temporal Service. Refer to Troubleshooting - Long Request Latency for guidance. - Low Schedule-to-Start latency and low CPU/memory: Depending on your workload, this could be normal. If you are consistently seeing low memory usage and low CPU usage, you may be over-provisioning your Workers and can consider scaling down.
Optimize Worker cache
Workers keep a cache of Workflow Executions to improve performance by reducing replay overhead. However, larger caches
consume more memory. The temporal_sticky_cache_size tracks the size of the cache. If you observe high memory usage for
your Workers and high temporal_sticky_cache_size, you can be reasonably sure the cache is contributing to memory
pressure.
Having a high temporal_sticky_cache_size by itself isn't necessarily an issue, but if your Workers are memory-bound,
consider reducing the cache size to allow more concurrent executions. We recommend you experiment with different cache
sizes in a staging environment to find the optimal setting for your Workflows. Refer to
Troubleshooting - Caching for more details on how to interpret
the different cache-related metrics.
Manage scale-down safely
Before shutting down a Worker, verify that it does not have too many active Tasks. This is especially relevant if your Workers are handling long-running, expensive Activities.
If worker_task_slots_available is at or near zero, the Worker is running active Tasks. Shutting it down could trigger
expensive retries or timeouts for long-running Activities. Use
Graceful Shutdowns to allow the Worker to complete its
current Task before shutting down. All SDKs provide a way to configure Graceful Shutdowns. For example, the Go SDK has
the WorkerStopTimeout option that lets you
configure the amount of time the Worker has to complete its current Task before shutting down.